The 360 customer view has long been a myth in the GTM world. In this article we break down the evolution of the ecosystem, and why now we're closer than ever to conceiving it.
TLDR: signup here, to see for yourself.
The old times#
Go-to-market people, marketers, and sales teams used to live in a world where a single database sufficed for most of their needs, often it was their CRM software.
That quickly changed as, over the past 20 years, omni-channel digital products flourished, we witnessed a Cambrian explosion of data about user behaviour 💥
Suddenly, businesses were recording customer data originating across many platforms - application databases, CRMs and marketing tools, offline interactions, and behavioural events collected directly from digital products.
Not leveraging all these potential insights was leaving a lot of money on the table.
👉 Thus was born the Customer Data Platform aka the CDP.
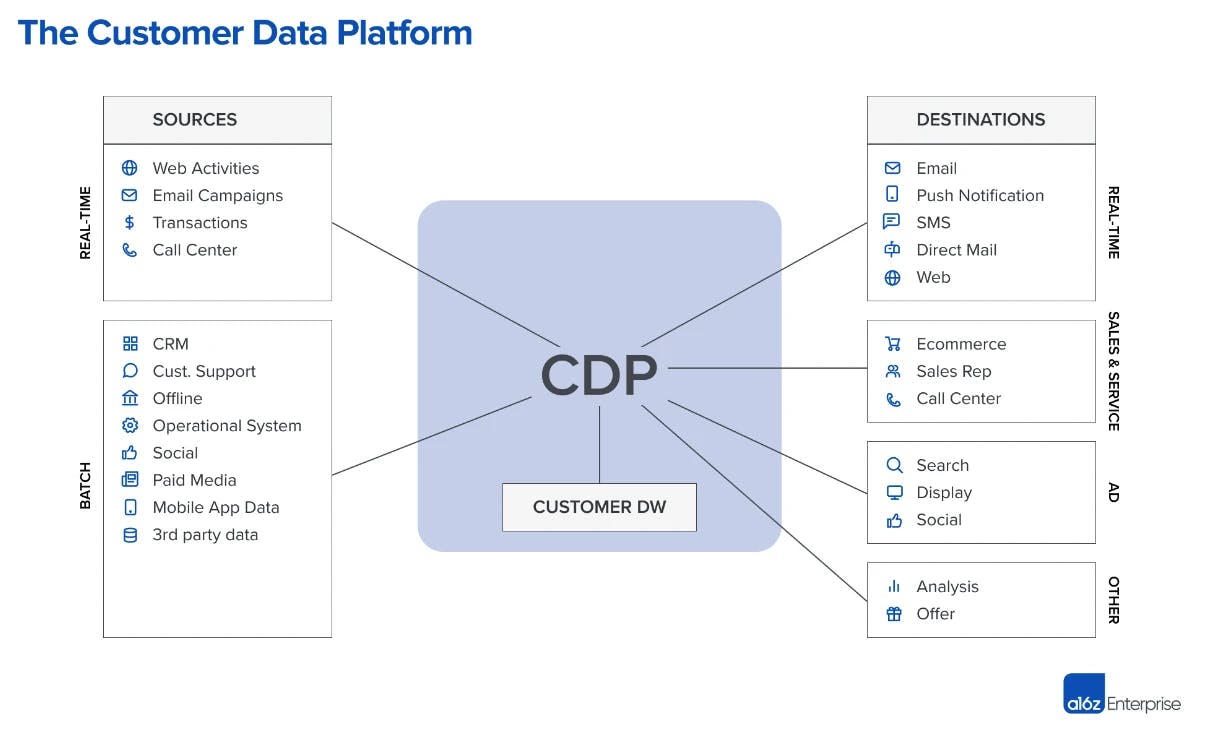
Starting around 2011, companies such as Twilio, Segment, Snowplow and Rudderstack revolutionised customer data collection by introducing what they called ‘identity resolution’.
👉 In basic language, it involves consolidating various data sets—from every customer interaction point—to create a unified data profile for each customer.
Behind this move was the long-awaited dream of building a 360° view of the customer. In other words, the crystal ball that would allow GTM teams to zero in to exactly when and how to engage the prospective customer (see below).
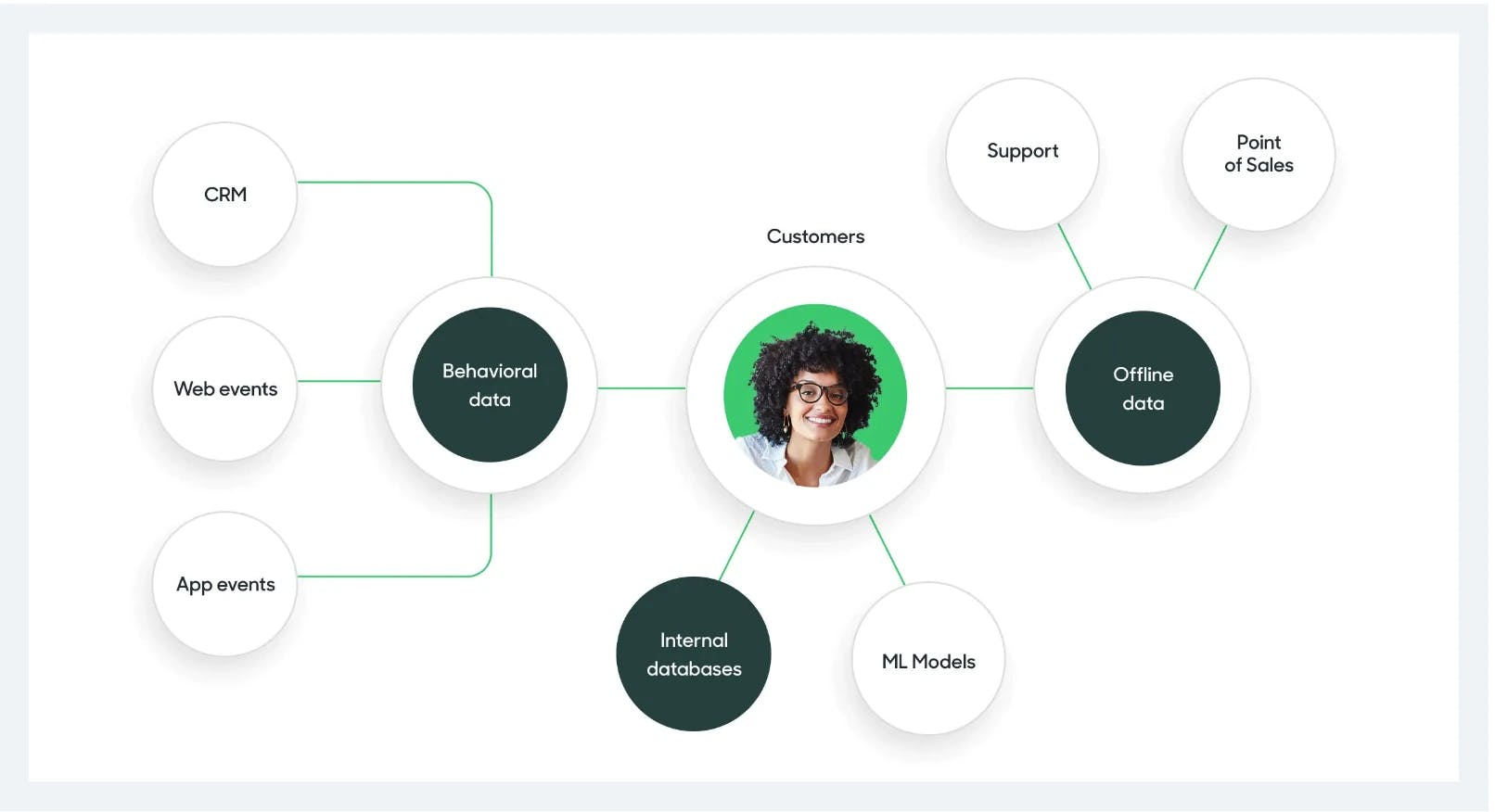 Illustration courtesy of High touch article
Illustration courtesy of High touch article
👉 Concretely speaking, the CDPs built an identity graph in the backend, a unified table that merges all user identifiers.
👉 On top, they built a no-code UI layer to let GTM users ‘activate’ the data using revenue-increasing actions.
GTM teams flocked to this proposition in droves.
Often, they would leverage it to evaluate their strategies as a function of customer behaviour and in response build workflows on top.
The dream of the 360° customer view had been achieved. Or had it?
The story did not end there, otherwise you would not be reading this article. The CDPs had fatal flaws that left the holy grail of the 360° yet unclaimed.
Why CDPs fell short of the promise#
If today the CDP institute reports that 90% of CDP users are not able to meet their operational needs from the technology, it is not surprising.
👉 The achilles’ heel of the CDP was in the rigidity of the design.
Consider this, a typical business entity’s identity resolution will vary significantly from their peers.
There’s a lot of custom logic needed in reconciling business account or workspace data, to merge records from diverse sources like in-app activities, CRMs, lead forms and more.
Even the most popular CDP systems like mParticle, Segment, Tealium, and Simon Data were not built to accomodate this flexibility in the ‘black-box’ like systems that they were selling.
❌ Instead they required businesses to collect data to fit to THEIR rigid schemas. Although this helped in creating universally simple onboarding journeys, these tools immediately struggled when businesses wanted to represent ‘entities’ other than just the standard one: users.
Even more annoyingly, these data systems were extremely brittle to changes and because they were built as black boxes, not accessible by on-site tech teams.
❌ Encounter a minor web tracking bug and you could see yourself spending 100+ hours of Segment professional services trying to reconfigure your entire system from scratch.
In most cases, it was more obvious to bin the entire CDP configuration and start over and reload all historical events into a new instance of the CDP, than to adapt an existing one.
❌ The consequence was that CDPs began to be used mostly for customer behavioural data while other data types were held across various alternative platforms.
👉 This violated the pre-requisite of a 360° view, i.e. data unification (see below)
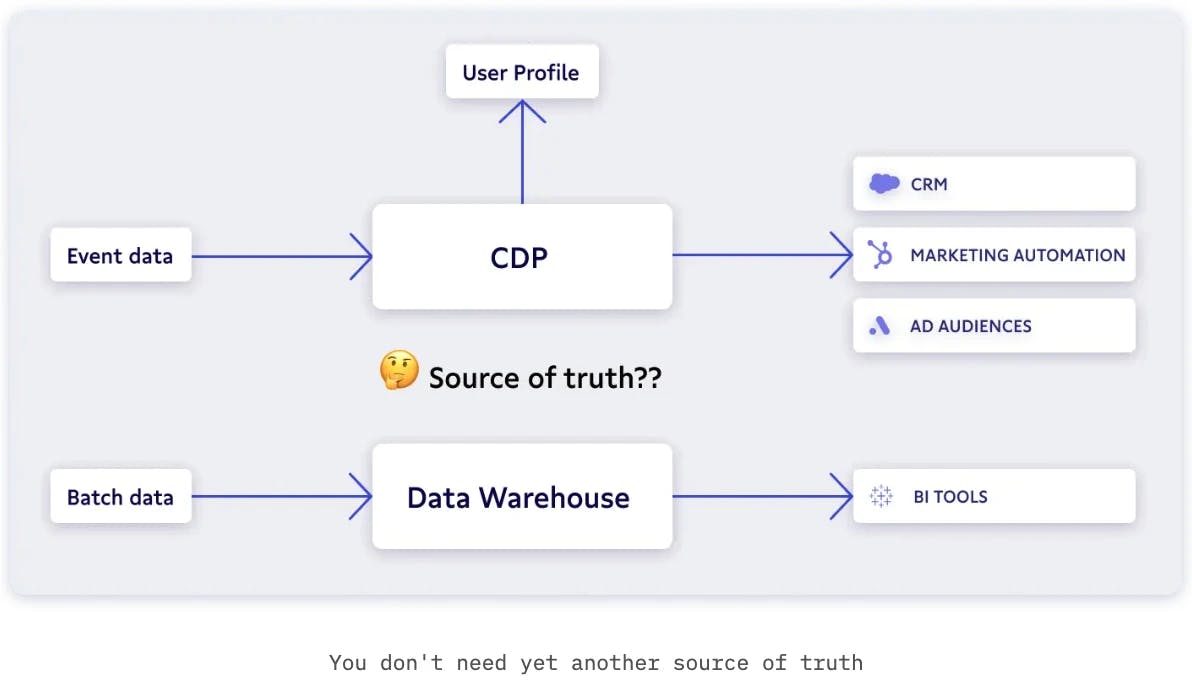 Illustration courtesy of Census article
Illustration courtesy of Census article
Enter: The Modern Data Stack
👉 At the same time, a powerful movement had already taken hold of most engineering and analytics teams, called the Modern Data Stack aka MDS.
Built on the same edifice of data unification, the MDS was instead built to be flexible enough for any use case across a variety of organisations, and also easily configurable by engineering teams using a neat stack of tools like Airbyte, Fivetran, Dbt, etc.
Although most organisations restricted themselves to using this stack primarily for analytics/reporting purposes, given the aforementioned pains of centralising GTM data in a CDPs, some of the braver ones began building local versions of the CDP on the MDS (like the one below.)
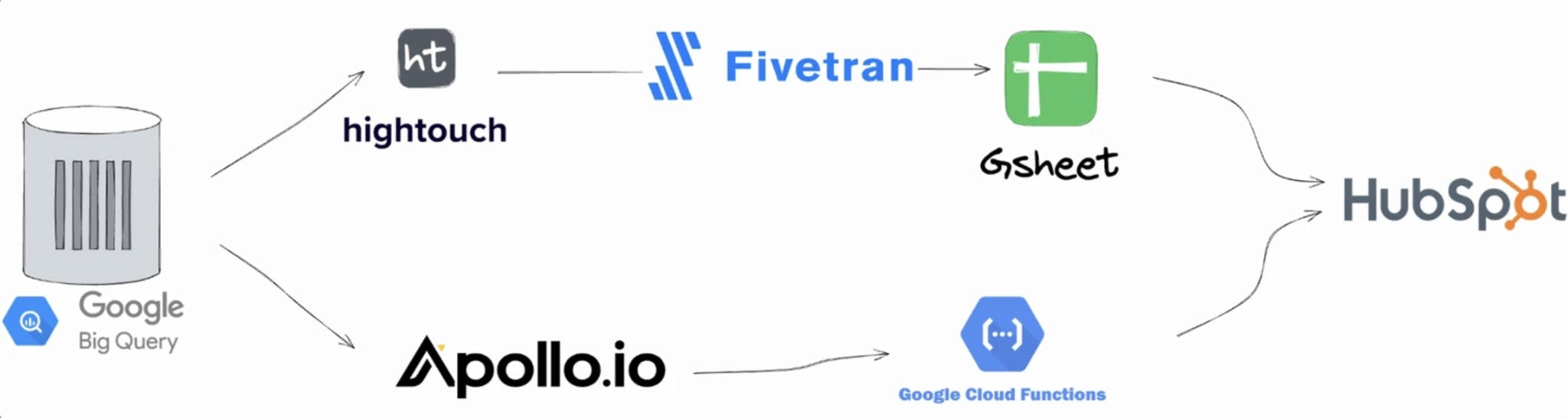
But this was a terribly painful, resource-heavy and error-prone exercise that necessitated a team of engineers available full time to the GTM teams to make sure this stack kept up and running.
Even sophisticated scale-ups like Rippling, Spendesk, Paddle, etc felt the pressure of keeping this up. Often this configuration broke at scale, or when there were not enough growth engineers around to maintain it 🤯
Imagine: A composable CDP#
👉 Sensing this, veterans from the CDP world dreamt up a new concept. The composable CDP was supposed to deliver the same promise of an easy to use 360° customer view to GTM teams, and although it sat on top of the MDS’s centrepiece - the data warehouse, it didn’t need any engineering resources to be maintained.
The composable CDP’s genius lay in its ability to co-opt the warehouse-first architecture that clients already possessed - and data teams already trusted, knowing they're not giving way to data chaos.
Meanwhile GTM folks could continue orchestrating their campaigns unhindered.
These were the three principles of a truly composable CDP:
-
Single Definitions: Dbt integration in composable CDPs ensures uniform metrics, simplifying feedback cycles.
-
No-code Interface: Drag-and-drop replaces verbose SQL, auto-generating needed commands for data warehouses.
-
Zero Copy: Eliminates data duplication, boosting security and fine-tuning access within client's warehouse.
The between times#
For every Messiah, there is inevitably a false one prior to muddy the waters.
For GTM folks, it was the promise of the Reverse ETL.
Their pitch was straightforward: if traditional CDPs struggled to integrate with various sales and marketing tools like Salesloft and Hubspot, why not just shuttle data directly from warehouses to these platforms?
While this was a neat ‘point solution’ which allowed metrics calculated with dbT to be sent to CRMs, it was a stopgap measure that undermined the original principles of CDPs.
Reverse ETLs ≠ composable CDPs

Despite the promise of no-code solutions, setting up pre and post-Reverse ETL still requires considerable coding expertise.
❌ Before data can be moved to the CRM, a data engineer is needed for data ingestion and unification. Notice, how in the illustration (from Census) above, Census only appears at the second-last step of the value chain.
❌ Additionally, the data sent to the CRM isn't immediately actionable. It often appears as a new column of data requiring further coding or manual labor to convert into a sales action.
Finally, reverse ETLs are most effective with a pre-defined, unified data definitions in the warehouse.
❌ If data comes from multiple or real-time sources, constant engineering intervention is needed to maintain coherence.
To their credit, Reverse ETLs have a short-time to value for those organisation testing our the data warehouse to feed their end-user engagement tools.
👉 But this remained only a point solution, with many pre-requisites, and lacked
the systematic value proposition that had made the original CDPs accessible to
all GTM teams.
A truly composable CDP aims to seamlessly unify data consolidation and
workflow orchestration in a user-friendly, no-code interface, while preserving
data integrity in the warehouse.
The promised land#
The team behind Cargo previously built a patchwork revenue orchestration system at Spendesk, using the best-in-class tech including the reverseETL.
Enter: Cargo
When this proved unwieldy, they redid it from scratch, in their own code, into what now serves as the robust back-end for the Cargo platform (see below).

Partisans of the composable CDP cult, we built the platform on the following principles:
-
No-code ingestion and unification 'out-of-the-box':
Extending the no-code approach to entity creation, Cargo empowers sales operations teams to easily define and manipulate data objects, such as identifying a "reverse champion prospect."
The result: complex intricate data processes run seamlessly in the background.
-
Complete data activation within the platform:
With just a 15-minute setup inside the data warehouse, Cargo acts as an activation layer, interfacing with top-tier engagement tools where sales teams already operate.
The result: a cohesive, no-code experience from notifications to custom workflows.
-
Leverage existing data infrastructure:
Working natively with your data warehouse for the backend, modularly build your engagement stack on the frontend.
The result: avoid the pitfall of vendor lock-in while allowing for easy maintenance, swaps and updates.
The advantage of choosing a best-of-breed tool like Cargo is that you get the cream of the crop of engagement tools:
🚢 Launch sequences in Outreach, Lemlist, LGM, etc.
🚢 Fed by your favorite data/enrichment providers (Apollo, Clearbit, Captain data, you name it).
🚢 Orchestrate, as you like, for your lead scoring or lead assignment.
🤖 Fan favourite: leverage AI, wherever along the way, using our native GPT plugin.
That is what we call a headless, composable CDP. Signup here, and we'll get you onboard.
 TariqJan 1, 2024
TariqJan 1, 2024