You’re a GTM person, managing a bunch of tools on top of your CRM, and feel like you’re always racing to stay on top of your data?
You’re not alone, and if you look under the hood of the stack of your tools, you'd notice that there’s massive web of API calls threading the various components together in a precarious balance.
This is not odd.
APIs are the core of the internet, and this patchwork has served us for a time, but this will article will demonstrate that, as a marketer, many of your daily struggles are emerging from this architecture.
TLDR: it's ETL-native. Find out more here.
Your technology stack is held together by duct-tape#
The reason?
APIs create a mesh of integrations between all your tools, spreading your data across different storages, each with overlapping scopes. All this mess leads to the inaccuracies, duplications, and data ambiguities that make you tear your hair out.
At Cargo, we think this paradigm is due for a shake-up.
👉 What will be different: ETL. A process that extracts data from one place, transforms it into a usable format, and loads it into another place, keeping both data sources in sync.
👉 The future of GTM tools is to decouple storage from the application layer.
👉 Once we’re there, the GTM person, will be dealing with much clearer customer insights and delivering precise, well-time conversations to your customers.
Let’s dive in…
How we got here#
By the early 2000's, the leading software products like Salesforce, eBay, and Amazon were all built leveraging an API-enabled architecture.
What does that mean?
An application is, simply, a computer program that a user interacts with to accomplish some task or perform an activity. An enterprise application like Salesforce provides opinionated frameworks for how a specific business function or business process should be done, and enables you to do (some portion of) those tasks.
👉 To support this, platforms like Salesforce introduce a 'data model'.
This model offers Sales and GTM teams a method to monitor product sales processes with clients, along with related analytics and metrics. It manages pivotal client data for an enterprise, covering current clients, deal amounts, client engagements, and the progress of potential clients throughout the sales journey.
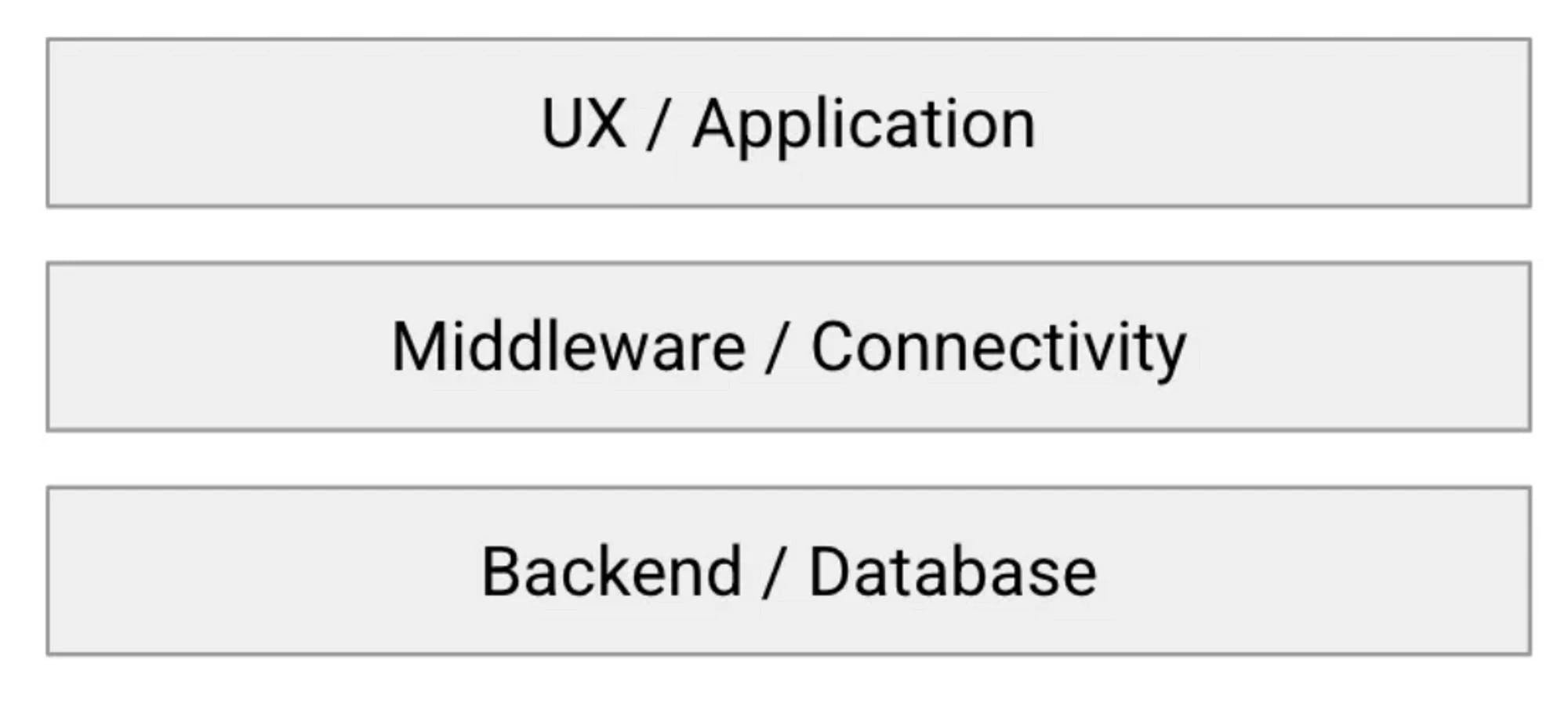
If we decompose the ingredients of what Salesforce constitutes, it is a sum of the:
- UX that end users interact with (the app itself)
-
API-based middleware that connects that application to the back end
-
the backend/databases, where the data itself is stored
To be functional in any company, all enterprise applications like Salesforce need a way to interact with the other technologies in the stack.
That means that every enterprise product was built on top of a jungle of API calls criss-crossing each other to keep data flowing across the system.
That was a great approach and it was one of the reasons for the rapid development of web applications across the internet.
Slowly, however, every organisation started stacking dozens and dozens of these software on top of each other, problems started to appear.
At Cargo, when we talk to our prospects for the first time, we can easily spend 10 mins just describing the ‘stack’ of tools that the GTM team is using to generate revenue. There are so many combinations and nuances that, after having spoken to hundreds of teams, we’re still never bored.
Despite all these possible combinations, the goals of all GTM teams are roughly similar, to identify the right prospects and use data to deduce the right message and timing to reach out to them.
👉 The trouble is that as the tools they use to gather and utilise that data are stacked on top of each other, thousands of API calls that drive them start interacting with each other. The quality of customer data is the major casualty.
Why APIs are failing GTM#
If you're reading this, you've likely experienced the symptoms of the underlying problems of customer data quality.
Turns out, APIs are adept at connecting various systems, however they're often far from perfect when it comes to ensuring data consistency and reliability across systems at scale.
Here's why:
Imagine an internet user arrives on your landing page and:
-
fills out a Typeform,
-
The Typeform API ships this data to Hubspot using their API,
-
This probably triggers a workflow that terminates by creating a Salesforce contact to be assigned to your sales rep (another API call).
-
that rep will likely receive this lead in an end-user tool like Outreach (ofc, another API call) to be able to send an email getting the user to a live demo
As the initial data point has now been tossed around multiple API routes, its traces are now found across all the four systems involved, who have applied their own interpretation at each point.
👉 The first problem is data ambiguity. Each round of API calls can sometimes act like overzealous translators. They transmit the data but after adding their own nuance at every step. Complexity grows exponentially with every step in the process. This makes it tough for teams trying to keep track of how data flows, where it originates, and how it might be transformed along the way.
👉 The second problem is maintainability. APIs are not set-it-and-forget-it tools. They need regular monitoring, updates, and troubleshooting. Every new tool added to the GTM stack generally means another set of API integrations. Every fix becomes harder to pull off.
👉 Third challenge with APIs are rate limits. Just like a busy highway can only handle so many cars at once, APIs have a cap on how many requests they can handle in a given time frame. When systems need to frequently exchange large volumes of data, they might hit these rate limits, leading to delays or even missed data transfers. This not only disrupts the seamless flow of data but can also result in incomplete or outdated information across systems
These three weaknesses translate directly to your daily woes.
As GTM motions rely more and more on a deeper, more nuanced understanding of customer data, the need for a more evolved, and holistic approach to unifying data becomes clear.
And that's where we think an ETL-native stack makes a lot more sense.
The ETL-native stack decouples storage from the UX layer
Our experience building Cargo with our first clients is that, in an API-first revenue stack, what starts off as a data-silo problem quickly snowballs into a people and team-collaboration problem.
Sales teams can't make informed decisions if they don't know the source of their data. In turn, that blocks them from taking action. That inefficiency costs the organisation a lot of money.
👉 A true sync between all your revenue tools, on the other hand, allows an organisation to collect all their different data sources into one place and thus define what data point means what.
For a sales team, that means knitting together all customer behaviour and sales process data into one observability layer.
Contrary to the API-first architecture, where applications operated in isolation and depended on APIs for disjointed integrations, ETL-native applications are architecturally designed to seamlessly extract, transact, and load data, ensuring a comprehensive, unified view at all times.
Beyond just reading from data warehouses, these applications actively interact, update, and curate the data.
This constant feedback loop ensures that all insights are up-to-date, synchronised, and relevant, paving the way for real-time decisions and actions.
Remember the illustration above where we decomposed Salesforce into the UX, the API middleware and the backend?
The new wave of ETL-native apps that we now expect to dominate enterprise applications will be using an ETL + reverse-ETL middleware to decoupling the backend from the UX layer.
👉 That means that enterprise applications will use YOUR data warehouse as their backend/storage (unlike today where their storage is the default).
If all of your enterprise applications are unifying themselves on your data warehouse, then we won't need to be facing the limitations of the API middleware.
It's early days, but it's already happening.
ETL-native applications: Stripe leads the pack

As a market leader in payments, Stripe saw the advantage of offering to sit directly on customers’ data warehouses in order to allow them to tap into the massive store of insights that Stripe was collecting on their paying customers.
The result?
They’ve already recruited the most data-savvy companies like Lime, Hubspot, Zoom, and ChowNow, who can now use the platform to automate downstream reporting and test new growth avenues with this data.
Bridging GTM Tools with Cargo#
But it's not just about unearthing insights in an individual tool like Stripe. Surely, others like Outreach and Customer.io are following in Stripe's footsteps by adding a native-ETL functionality.
Enter: Cargo

We see it as this: Big platforms like Stripe excel at enhancing the warehouse experience. But with numerous top-notch GTM tools emerging each year, the market demands a versatile and unbiased platform that effortlessly integrates with the data warehouse for all your GTM needs.
For pre-sales, marketing, and/or customer success, Cargo layers itself atop your data warehouse. This ensures a smooth sync of data, insights, and analytics across the entire stack of GTM tools.
The key innovation is that now with Cargo’s infrastructure, any organisation with a data warehouse can pull this off without requiring an army of engineers to maintain the stack. Once done, you can seamlessly:
🚢 Launch sequences in Outreach, Lemlist, LGM, etc.
🚢 Fed by your favorite data/enrichment providers (Apollo, Clearbit, Captain data, you name it).
🚢 Orchestrate, as you like, for your lead scoring or lead assignment.
🤖 Fan favourite: leverage AI, wherever along the way, using our native GPT plugin.
That is what we call a headless, composable CDP.
Signup here, and we'll get you onboard.
 TariqJan 1, 2024
TariqJan 1, 2024